自然言語処理を応用した化学情報の予測
プロジェクト概要
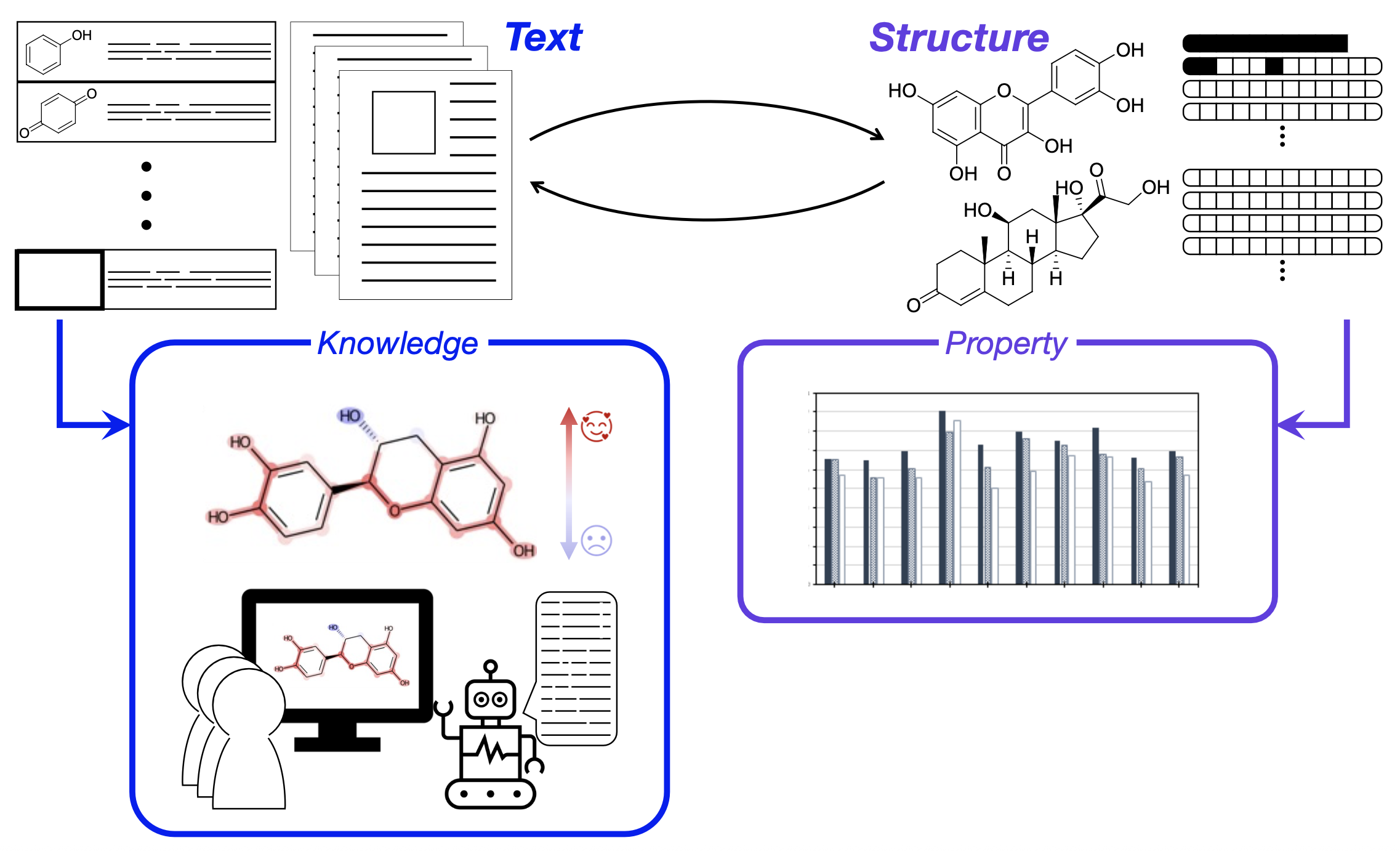
このプロジェクトでは、ChatGPTやGeminiなどの『生成AI』にも広く応用されている自然言語処理(Natural Language Process, NLP)という人工知能技術を活用することで、日々世界中で発表される膨大な量の化学論文やデータベースに含まれる化学的情報を効率的に引き出し、そこで引き出された情報を用いた分子の物性予測や新規分子の設計の更なる高度化を目指して研究を行っている。
研究内容
1. 背景
(1) 外挿性, 解釈性
従来の化合物の活性予測モデルには、次の2つの大きな課題があった。
- 外挿性: 予測モデルを作成しても、学習データに含まれていなかった分子に対する予測性能が低い。
- 解釈性: モデルによる予測が得られても、なぜその予測が出たのかが明瞭でない。
本プロジェクトにおける過去の研究では、化学的な論文内の情報(集合知)の中に、化合物の構造や特性に関する重要なヒントが隠されているという知見が得られており、このことを基にして、論文やデータベースの情報の積極的な活用を行なっている。
(2) 膨大な情報量
化学の分野では、新規の論文が年間数十万報も発表されており、それに伴ってデータベースの規模も拡大してきている。そのような中で、更なるイノベーションを生み出すためにも「研究者が独力であらゆる情報にアクセスして研究を進める」のは理想的ではあるが、それは非現実的であり「研究者がアクセスしきれない情報の存在による損失」が生じているといえる。自然言語処理技術を活用して、論文等から収集された情報を研究開発に活かすことで、この「損失」の低下、つまり研究者がアクセスできる情報の範囲の拡大が期待される。
(3) 既存研究との独立性
一般的な機械学習モデルには既存研究による知見が含まれることは稀である。これは、機械学習モデルにおいて入れる情報や学び方がそのモデルに依ってしまうこと、及び数字で表せない情報を含めることが困難であり、研究者の知識を完全に入れ込むことが難しいからである。言語情報はそれらのあやふやな情報をあやふやな状態で処理することができ、知見や知識に沿った学び方を可能にする。
2. 研究手法と具体的テーマ
(1) 文書情報に基づく化学知識の抽出と定量化
- 化合物の抗酸化能に関する論文・計1,744報を、言語モデルWord2Vecにより解析し、各化合物名に対応する埋め込み表現(補足1)を取得した。この埋め込み表現が、その化合物に対する化学的・構造的な性質と強い相関を有するということを確認した。
- 文書情報をもとに潜在空間(補足2)内で分類されたクラスターを分析し、特定のクラスターが、特定の共通構造、抗がん作用などの特定の活性を共通に有する化合物で構成されていることを確認した。
- 論文の文脈において「類似している」と判断された(補足3)化合物同士について、それらの実際の化学構造も類似しているということを定量的に示した。
(2) 構造情報と文書情報の統合による高精度な予測: Fp Doc2Vecモデル
- 化合物がもちうる生物学的役割・計10種類(抗酸化能, 毒性など)について、その化合物の構造と論文情報に基づいた分類予測を試みた。
- Doc2Vecと呼ばれる自然言語処理モデルをベースとして、その化合物の部分構造(分子フィンガープリント, 補足4)も取り入れたFp Doc2Vecというモデルを開発した。このモデルでは、化合物の構造的特徴とその機能的記述を両方含んだ特徴量が使用された(補足5)。
- 従来の構造情報だけを用いた予測に比べて、化合物の多くの生物学的役割の分類予測精度が向上した。さらに、文書の学習に使用されない新規化合物に対しても高い予測性能が示された。
- モデルの予測結果に各特徴量がどう寄与したかを定量的に可視化できるSHAPを活用し、予測に対して強い影響を与えた具体的な部分構造を同定した。
(3) 新規な言語モデルの活用
- 複雑な文章の文脈や専門的な化学用語を捉えたより高性能なモデルを構築するため、大規模言語モデル(Large Language Model, LLM)といった「比較的新しい」言語モデルを活用した研究も進めてきた。
- 特に、大規模言語モデルBERTを活用した場合、それよりも「比較的古い」言語モデルであるDoc2Vecに比べて、生物学的役割の分類予測をより高精度に行うことができると確認した。
補足
- 埋め込み表現とは、入力情報(ここでは化合物名)を、コンピュータが効率的に処理できるように、低次元の実数値ベクトルに変換したものである。
- 潜在空間とは、これらの埋め込み表現が配置されるベクトル空間を指す。意味的・構造的に近いデータ同士がこの空間内で集まってクラスターが形成される。
- ここで「類似している」という判断は、潜在空間内において、ベクトル(各埋め込み表現が対応する)同士の距離が近いということに基づいている。
- 分子フィンガープリントとは、分子における特定の部分構造の有無を、0または1のビット列(ベクトル)として表現したものである。
- テキスト情報と化合物構造情報に基づく機械学習のような、形式の異なるデータを統合して扱う機械学習手法をマルチモーダル学習という。
応用・今後の展望
- 所望の活性に対して強く寄与する分子の部分構造が分かれば、研究者はその情報に基づいて、より効率的に新しい分子を設計・合成できるようになる。
- 新しく設計された分子の役割や活性を予測可能なモデルを活用することで、実験を行う前に所望の分子として有望なものを効率的に見つけることができる。
- 新規論文を取り入れてモデルを更新することは可能であり、最新の状況を反映させたモデルの活用が可能である。
研究室配属にあたって
このテーマは、こんな人に向いています
- 自分らしさを出せる「個性的」な研究がしたい!
- プログラミングが好き!
- ChatGPT, Geminiなどの『生成AI』に興味がある!
- ケモインフォマティクスに将来性を感じる!
- これまで学んできた化学の知識を、デジタル的に活用したい!
関連論文
- Compound Classification and Consideration of Correlation with Chemical Descriptors from Articles on Antioxidant Capacity Using Natural Language Processing
JCIM, 2024, Vol. 64, No. 1, pp. 119
※ 本記事は、ChatGPT-4oおよびNoteBookLMを使用して作成しています。